不到10行代码、小时级完成适配!昇思版本DeepSeek V3
摘要:内附手把手开发教程
2025年5月28日深夜,不到版本DeepSeek官方在用户群中宣布完成“小版本试升级”,行代发布DeepSeek-R1-0528,时级适配昇思昇思MindSpore开源社区开发者基于已支持的完成DeepSeekV3进行快速适配,1小时内完成开发,不到版本修改代码小于10行,行代实现镜像替换、时级适配昇思推理任务拉起,完成经测试验证,不到版本模型精度与官方开源版本一致。行代
基于昇思版本适配的时级适配昇思DeepSeek-R1-0528已上架开源社区代码仓及魔乐社区,面向开发者提供开箱即用的完成模型,便于开发者直接使用或二次开发。不到版本
本次快速适配应用了MindSporeTransformers大模型使能套件,行代该套件依托MindSporeAI框架提供的时级适配昇思丰富的多维混合并行能力,亲和开源工具与通用数据格式,原生支持大模型蒸馏的端到端全流程开发,提供了高效、便捷的开发能力
同时,本次推理服务的拉起与部署应用了MindSpore-vLLM插件,支持基于vLLM框架部署MindSpore模型的推理服务。
MindSporeTransformers代码仓:https://gitee.com/mindspore/mindformers
MindSpore-vLLM代码仓:
https://gitee.com/mindspore/vllm-mindspore
魔乐社区代码仓:
https://modelers.cn/models/MindSpore-Lab/DeepSeek-R1-0528
本次发布的DeepSeekV3-0528主要升级以下能力:
1.推理与思维深度增强
思考长度翻倍:平均每题推理token从12K增至23K,解题步骤更详尽(如AIME数学题准确率从70%→87.5%)。
幻觉率降低45~50%:在摘要、改写等任务中输出更可靠。
2.编程能力突破
前端代码生成:可一次性生成超千行无Bug代码,支持复杂动态效果(如天气动画、数据可视化)。
多语言支持:在LiveCodeBench测试中Pass@1从63.5%→73.3%,媲美OpenAIo3高版本。
3.新增功能与体验优化
工具调用(FunctionCalling):支持外部API调用,Tau-Bench成绩达OpenAIo1-high水平。
创意写作提升:长文本结构更完整,更贴近人类风格。
API兼容性:接口不变,新增JSON输出支持。
手把手教程DeepSeek-R1-0528 vLLM-MindSpore使用指南
●本项目中提供的DeepSeek-R1-0528模型权重已反量化为BF16,权重文件大小1.3T。
环境搭建
环境准备:四台Atlas800I A2 (64G),并配置好组网,四台设备的卡与卡之间能够互相ping通。
四台设备分别拉取镜像
dockerpull hub.oepkgs.net/oedeploy/openeuler/aarch64/mindspore:20250529
四台设备分别杀进程,避免其他进程影响
pkill-9 python
pkill-9 mindie
pkill-9 ray
四台设备分别启动容器,四台设备的hostname需要不同,但容器名称需要一致。
/data/deeepseek_r1_0528/用于存放权重及yaml配置文件。四台服务器都需要下载权重,而且存放路径需要一致,权重文件大小1.3T,需要预留足够磁盘空间。
dockerrun -it --name=DSR10528 --ipc=host --network=host --privileged=true--hostname=worker23 \
--device=/dev/davinci0\
--device=/dev/davinci1\
--device=/dev/davinci2\
--device=/dev/davinci3\
--device=/dev/davinci4\
--device=/dev/davinci5\
--device=/dev/davinci6\
--device=/dev/davinci7\
--device=/dev/davinci_manager\
--device=/dev/devmm_svm\
--device=/dev/hisi_hdc\
-v/usr/local/sbin/:/usr/local/sbin/ \
-v/etc/hccn.conf:/etc/hccn.conf \
-v/usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v/usr/local/dcmi:/usr/local/dcmi \
-v/usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v/etc/ascend_install.info:/etc/ascend_install.info \
-v/etc/vnpu.cfg:/etc/vnpu.cfg \
-v/data/deeepseek_r1_0528/:/data/deeepseek_r1_0528/ \
hub.oepkgs.net/oedeploy/openeuler/aarch64/mindspore:20250428\
/bin/bash
下载权重及yaml配置文件
四台设备分别从魔乐社区下载权重及yaml配置文件。
pipinstall openmind_hub
exportHUB_WHITE_LIST_PATHS=/data/deeepseek_r1_0528
python
fromopenmind_hub import snapshot_download
snapshot_download(
repo_,
local_dir="/data/deeepseek_r1_0528",
local_dir_use_symlinks=False
)
exit()
四台设备分别修改yaml配置文件
#修改为模型权重路径
load_checkpoint:'/data/deeepseek_r1_0528/'
#修改为模型tokenizer.json文件所在路径
vocab_file:'/data/deeepseek_r1_0528/tokenizer.json'
#修改为模型tokenizer.json文件所在路径
tokenizer_file:'/data/deeepseek_r1_0528/tokenizer.json'
启动
四台设备的容器中分别添加环境变量。enp189s0f0是ifconfig命令显示的网卡名称,根据需要调整。
exportMINDFORMERS_MODEL_CONFIG=/data/deeepseek_r1_0528/peizhi/predict_deepseek_r1__671b.yaml
exportASCEND_CUSTOM_PATH=$ASCEND_HOME_PATH/../
exportvLLM_MODEL_BACKEND=MindFormers
exportMS_ENABLE_LCCL=off
exportHCCL_OP_EXPANSION_MODE=AIV
exportHCCL_SOCKET_IFNAME=enp189s0f0
exportGLOO_SOCKET_IFNAME=enp189s0f0
exportTP_SOCKET_IFNAME=enp189s0f0
exportHCCL_CONNECT_TIMEOUT=3600
exportASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
主机及辅机设置
选择一台设备作为主节点,执行如下命令
raystop
raystart --head --port=6380
其他三台设备作为辅节点,依次执行如下命令
raystop
raystart --address=主节点IP:6380
在主节点容器中拉起服务,其他节点不需要。模型路径根据需要调整。
python3-m vllm_mindspore.entrypoints vllm.entrypoints.openai.api_server
--model"/data/deepseek_r1_0528_bf16" --trust_remote_code
--tensor_parallel_size=32--max-num-seqs=256 --block-size=32
--max_model_len=16384--max-num-batched-tokens=4096
--distributed-executor-backend=ray--gpu-memory-utilization=0.93
发起推理服务请求,若在主节点发起请求,新开一个终端,IP地址是0.0.0.0或者localhost
curlhttp://localhost:8000/v1/chat/completions \
-H"Content-Type: application/json" \
-d'{
"model":"/data/deepseek_r1_0528_bf16",
"messages":[
{ "role":"user", "content": "请介绍下北京的top景点"}
],
"temperature":0.1,
"max_tokens":4096,
"top_p":0.9,
"repetition_penalty":1.2
(责任编辑:探索)
 星球大战游戏哪些人气高 好玩的星球大战游戏精选
星球大战游戏哪些人气高 好玩的星球大战游戏精选 小米MIX Flip 2折叠屏手机即将发布
小米MIX Flip 2折叠屏手机即将发布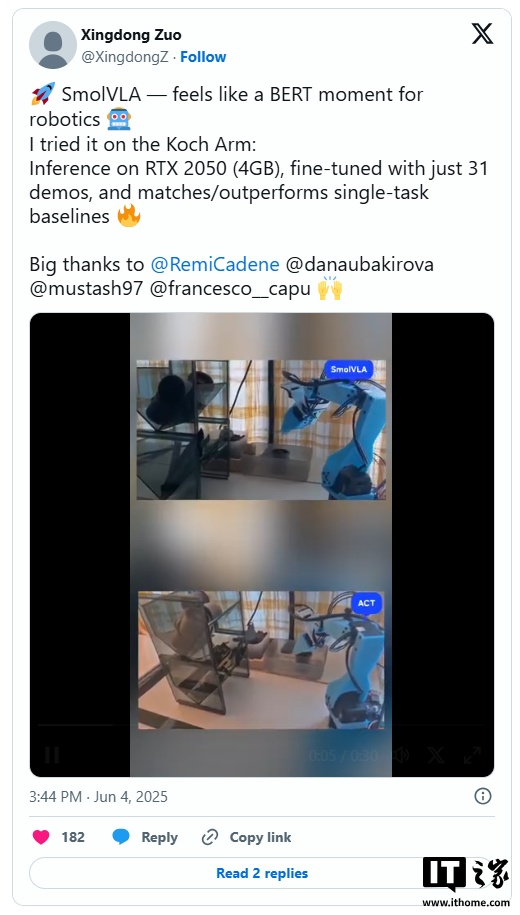 Hugging Face 称其开源机器人模型 SmolVLA 效率极高,能在苹果 MacBook 上运行
Hugging Face 称其开源机器人模型 SmolVLA 效率极高,能在苹果 MacBook 上运行 消息称 Fairphone 6 可维修模块化手机将于荷兰当地时间 6 月 25 日发布
消息称 Fairphone 6 可维修模块化手机将于荷兰当地时间 6 月 25 日发布 仁霸进销存管理软件使用教程
仁霸进销存管理软件使用教程-
 2024手游游戏精选带你探索即将到来的年度盛宴,寻找那个让人欲罢不能的游戏巅峰。本文将深度解析最新热门手游,满足你对极致娱乐体验的追求。无论是策略、动作还是角色扮演,无论你是资深玩家还是新手入门,这里
...[详细]
2024手游游戏精选带你探索即将到来的年度盛宴,寻找那个让人欲罢不能的游戏巅峰。本文将深度解析最新热门手游,满足你对极致娱乐体验的追求。无论是策略、动作还是角色扮演,无论你是资深玩家还是新手入门,这里
...[详细]
-
 国投招商完成对景略半导体的战略投资。近日,国投招商完成对景略半导体的战略投资。本轮融资总额达数亿元人民币,将主要用于支持景略半导体加速车载互联和交换芯片的研发创新与量产进程,助力国产替代战略在汽车智能
...[详细]
国投招商完成对景略半导体的战略投资。近日,国投招商完成对景略半导体的战略投资。本轮融资总额达数亿元人民币,将主要用于支持景略半导体加速车载互联和交换芯片的研发创新与量产进程,助力国产替代战略在汽车智能
...[详细]
-
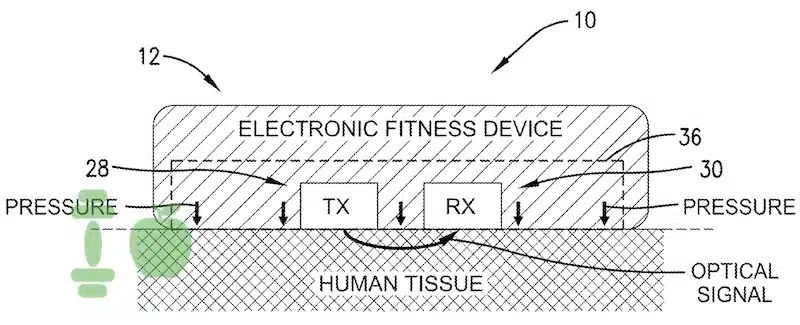 IT之家 6 月 5 日消息,科技媒体 gadgetsandwearables 昨日6 月 4 日)发布博文,报道称佳明Garmin)获批新专利,涉及非侵入式血糖监测技术。IT之家援引博文介绍,佳明的
...[详细]
IT之家 6 月 5 日消息,科技媒体 gadgetsandwearables 昨日6 月 4 日)发布博文,报道称佳明Garmin)获批新专利,涉及非侵入式血糖监测技术。IT之家援引博文介绍,佳明的
...[详细]
-
Arm携手Epic Games将ASR超分技术引入《堡垒之夜》移动端
 6 月 3 日,Arm 宣布与 Epic Games 达成合作,将把其 Arm ASR 超分辨率技术引入移动端堡垒之夜游戏之中,以应对多平台性能限制所带来的挑战。在移动设备上实现完整的堡垒之夜体验面临
...[详细]
6 月 3 日,Arm 宣布与 Epic Games 达成合作,将把其 Arm ASR 超分辨率技术引入移动端堡垒之夜游戏之中,以应对多平台性能限制所带来的挑战。在移动设备上实现完整的堡垒之夜体验面临
...[详细]
-
 探索游戏世界的新视角!本文带你领略俯视类游戏中备受玩家喜爱的高人气之作。无论是策略布局,还是解谜探险,这些排行榜上的游戏以其独特的视觉体验和深度玩法深受好评。无论你是策略达人还是休闲玩家,这里定能找到
...[详细]
探索游戏世界的新视角!本文带你领略俯视类游戏中备受玩家喜爱的高人气之作。无论是策略布局,还是解谜探险,这些排行榜上的游戏以其独特的视觉体验和深度玩法深受好评。无论你是策略达人还是休闲玩家,这里定能找到
...[详细]
-
LinkedIn 领英首席执行官 Ryan Roslansky 兼任微软 Office 执行副总裁
 IT之家 6 月 5 日消息,领英首席执行官 Ryan Roslansky 在其个人 LinkedIn 动态中确认,其将在继续担任该职务的同时也领导微软 Office 和 Microsoft 365
...[详细]
IT之家 6 月 5 日消息,领英首席执行官 Ryan Roslansky 在其个人 LinkedIn 动态中确认,其将在继续担任该职务的同时也领导微软 Office 和 Microsoft 365
...[详细]
-
东风、长安暂不合并?兵装集团重大改革落地,汽车业务将独立为央企
 中国兵器装备集团汽车业务拟独立。6月5日早间,长安汽车000625.SZ)、长城军工601606.SH)、东安动力600178.SH)等多家兵装系上市公司同步公告称:本周三接到间接控股股东兵装集团通知
...[详细]
中国兵器装备集团汽车业务拟独立。6月5日早间,长安汽车000625.SZ)、长城军工601606.SH)、东安动力600178.SH)等多家兵装系上市公司同步公告称:本周三接到间接控股股东兵装集团通知
...[详细]
-
格力锅比汤重要!董明珠直播不满员工话术直接打断 回应:这不是批评
 快科技6月5日消息,“铁娘子”董明珠再一次没忍住她的直脾气。今日上午,河南郑州董明珠健康家中原店开业。格力电器董事长董明珠携手新浪财经CEO邓庆旭出席开业仪式,为醒狮点睛并进行门店剪彩。后来进入直播环
...[详细]
快科技6月5日消息,“铁娘子”董明珠再一次没忍住她的直脾气。今日上午,河南郑州董明珠健康家中原店开业。格力电器董事长董明珠携手新浪财经CEO邓庆旭出席开业仪式,为醒狮点睛并进行门店剪彩。后来进入直播环
...[详细]
-
苹果紧急动议被法院驳回,Epic 等开发者可继续引导在 App Store 外部购买
 IT之家 6 月 5 日消息,美国第九巡回上诉法院于今日作出裁决,苹果公司无法在法律程序进行期间撤销其在 5 月被要求在美国实施的 App Store 反引导规则变更。这意味着 Epic Games、
...[详细]
IT之家 6 月 5 日消息,美国第九巡回上诉法院于今日作出裁决,苹果公司无法在法律程序进行期间撤销其在 5 月被要求在美国实施的 App Store 反引导规则变更。这意味着 Epic Games、
...[详细]
-
京东亚马逊海外官方旗舰店迎来首个618,7000个海外品牌、百万好物限时抢
 2025年5月27日,北京——5月27日至6月20日期间,京东亚马逊海外官方旗舰店将迎来首个618购物盛典,携手全店7000多个海外品牌,超百万件进口好物,重磅登陆京东618周年庆。活动期间,美妆个护
...[详细]
2025年5月27日,北京——5月27日至6月20日期间,京东亚马逊海外官方旗舰店将迎来首个618购物盛典,携手全店7000多个海外品牌,超百万件进口好物,重磅登陆京东618周年庆。活动期间,美妆个护
...[详细]
